And we are back! … with some slightly underwhelming results.
After feeding our data to our nifty little classifier, we have gotten a set of unexpectedly positive results. Out of all the books we fed to our hungry, hungry algorithms, we learned that a whopping 49 of them were positive, with a meager 2 negatives and 2 inconclusive results… Here’s the data:
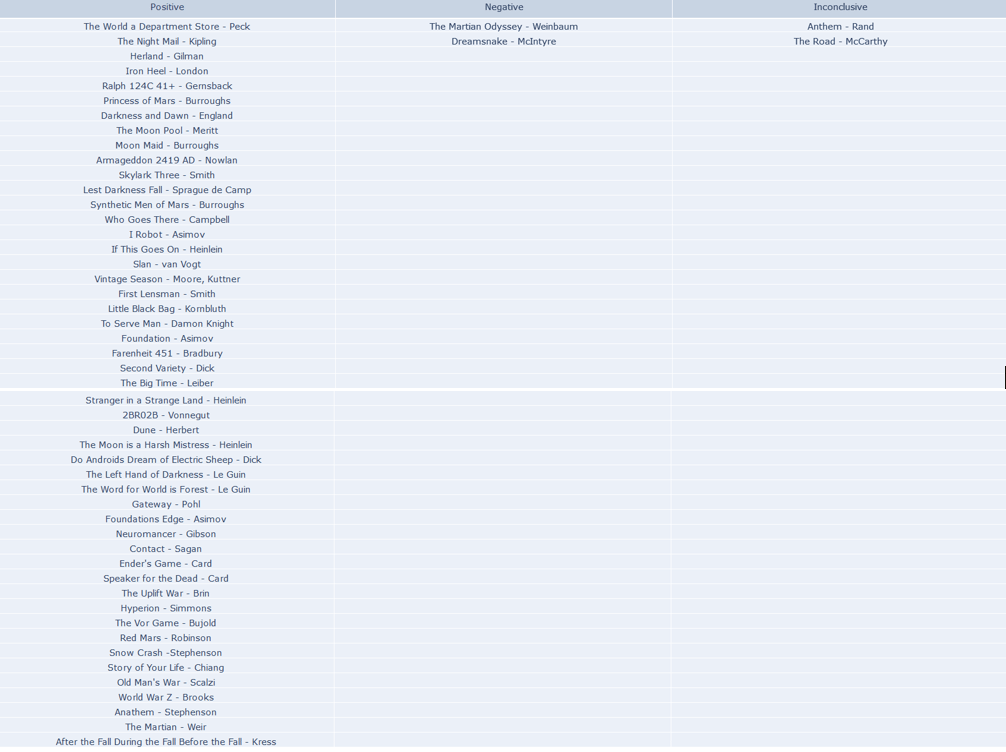
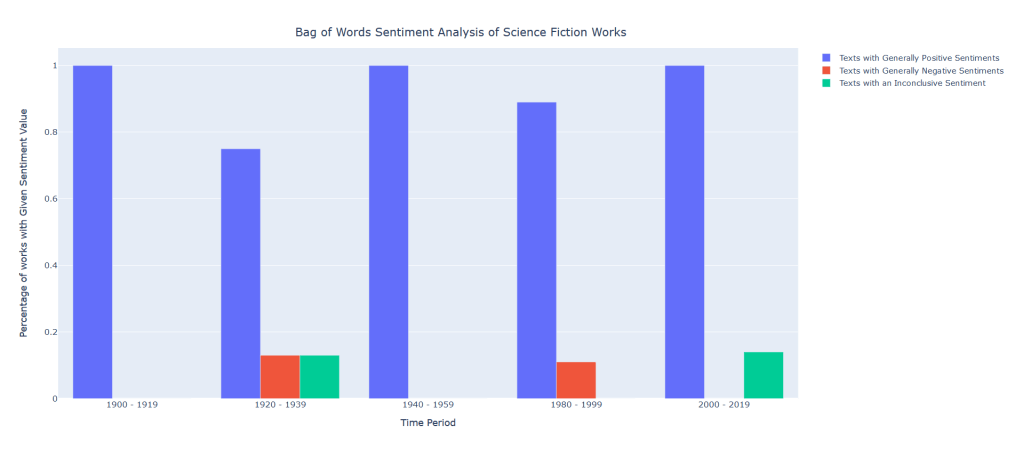
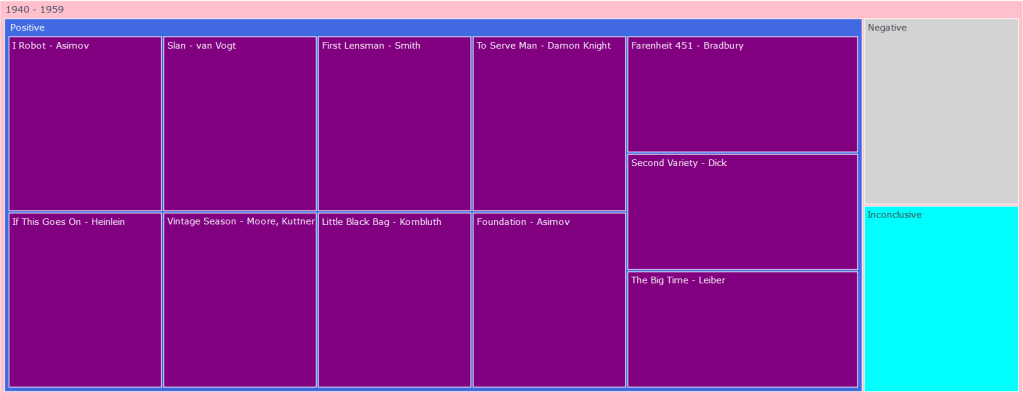
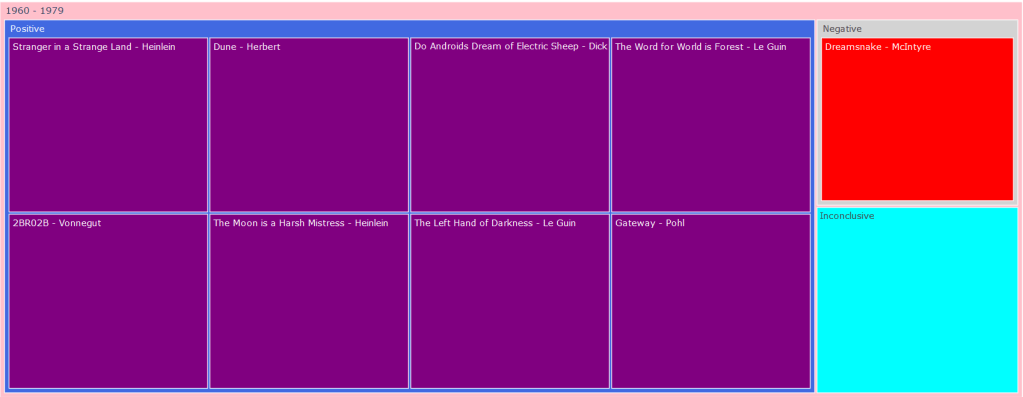
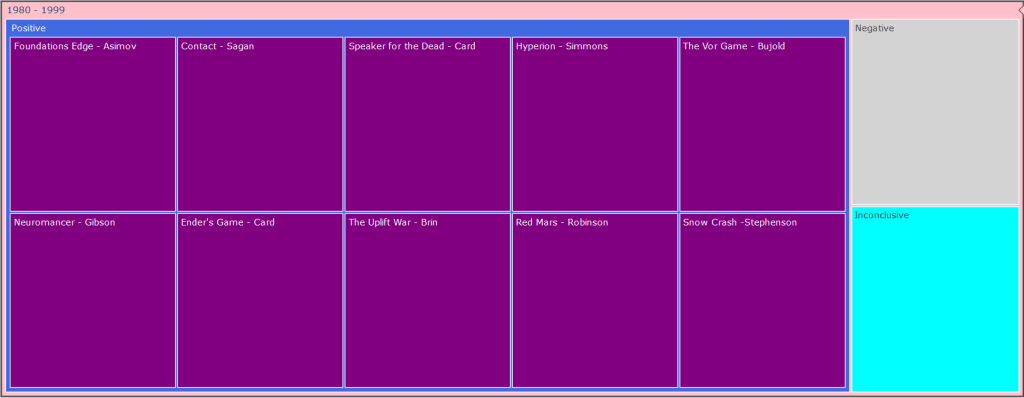
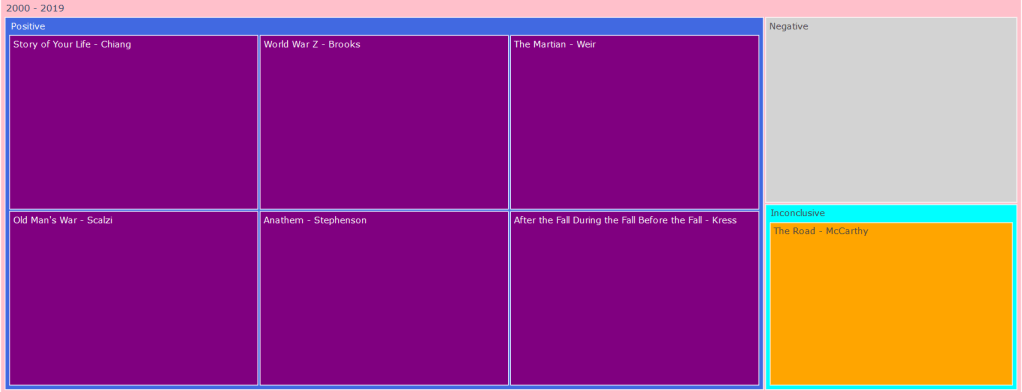
That seems a little off doesn’t it? What happened to the dark and edgy science fiction dystopia of control and despair, in which the occupants hung their heads in misery and sorrow? Where did all these rays of sunlight and double rainbows come from? Something must have gone wrong. Is our voted_classifier algorithm broken? Is our data-set get messed up somewhere along the way? Are we all just living in a simulation?
I think the answer to this question lies in the way we pre-processed our data. For this first phase of sentiment analysis, we chose to use a bag-of-words representation in which we tokenized the entire work into its individualized words. This is easy for our classifiers to eat up and take in, but as discussed earlier in the sentiment analysis post, when we utilize this method, our words lose their context. Certain adjectives placed next to certain nouns or adjectives completely alter the meaning of a phrase, but in these circumstances, we completely lose them. Science fiction is also a very difficult literary form for this form of classification to understand due to the sheer amount of social commentary it provides in tongue-in-cheek fashion. Furthermore, the various dystopian and utopian societies our characters often find themselves in are described to be cheery and happy on the surface level much of the time, thus tripping up our poor little algorithm
So is this the end? Is there no other way to get a nice and tidy analysis of these ‘classic’ science fiction works? Not at all. This form of sentiment analysis is one of the most rudimentary forms. We’ve rounded out our data-set, figured out all the logistical bits of this task, and now we can just feed our data (pre-processed in a different manner of course) through different sorts of sentiment analysis machinery.
Here are some alternative paths we could take:
- Tokenizing the work by sentence, applying our current voted classifier to each sentence, and then determine a general sentiment polarity by aggregating all of our sentences.
- Utilizing deep learning/other AI processes to develop our sentiment analysis algorithm. There is quite a bit of machinery for this: We can try out basic neural networks, convolutional neural networks, recurrent neural networks, and other varieties
- Processing our data as n-grams: An n-gram is a set of n-words (tri-gram is a set of three words such as “He is tired”, a bi-gram is a set of two words “Dog died”). This preserves a bit of context in the form of phrases and does not make our data overly chunky.
So despite this slightly confusing initial output, there is still much more road to travel on. The voted classifier of various NLTK algorithms we used for this classification is but a rudimentary manner of classification that works well as a baseline for more simplistic and ‘unliterary’ phrases, but will struggle when presented with some more challenging and artistic pieces of writing. Outside of this binary positive-negative relationship, we can also go the way of positive-negative magnitude as well as emotion. With the data-set all tidied up and the general workflow fleshed out, we can explore another range of algorithms and techniques that will most likely provide us with much more accuracy and specificity.

Leave a comment